CADMonkey

Training a Language Model to generate 3D files from text.
Background
Over my whole career, I have worked as a Mechanical Engineer, Robotics Engineer, Plumbing Engineer, Software & AI Engineer. A consistent thread is that physical things take longer and more effort to create than software.

Armed with GPU credits from CloudRift & Prime Intellect + the generous free usage of Huggingface, I set out to build a language model to generate 3D files.
Model Architecture & 3D Language
At Starmind, we need our models to be small enough to run on Raspberry Pi 4 & 5. We picked Gemma3 due to its high intelligence and diversity of model sizes (270M, 1B, 4B).
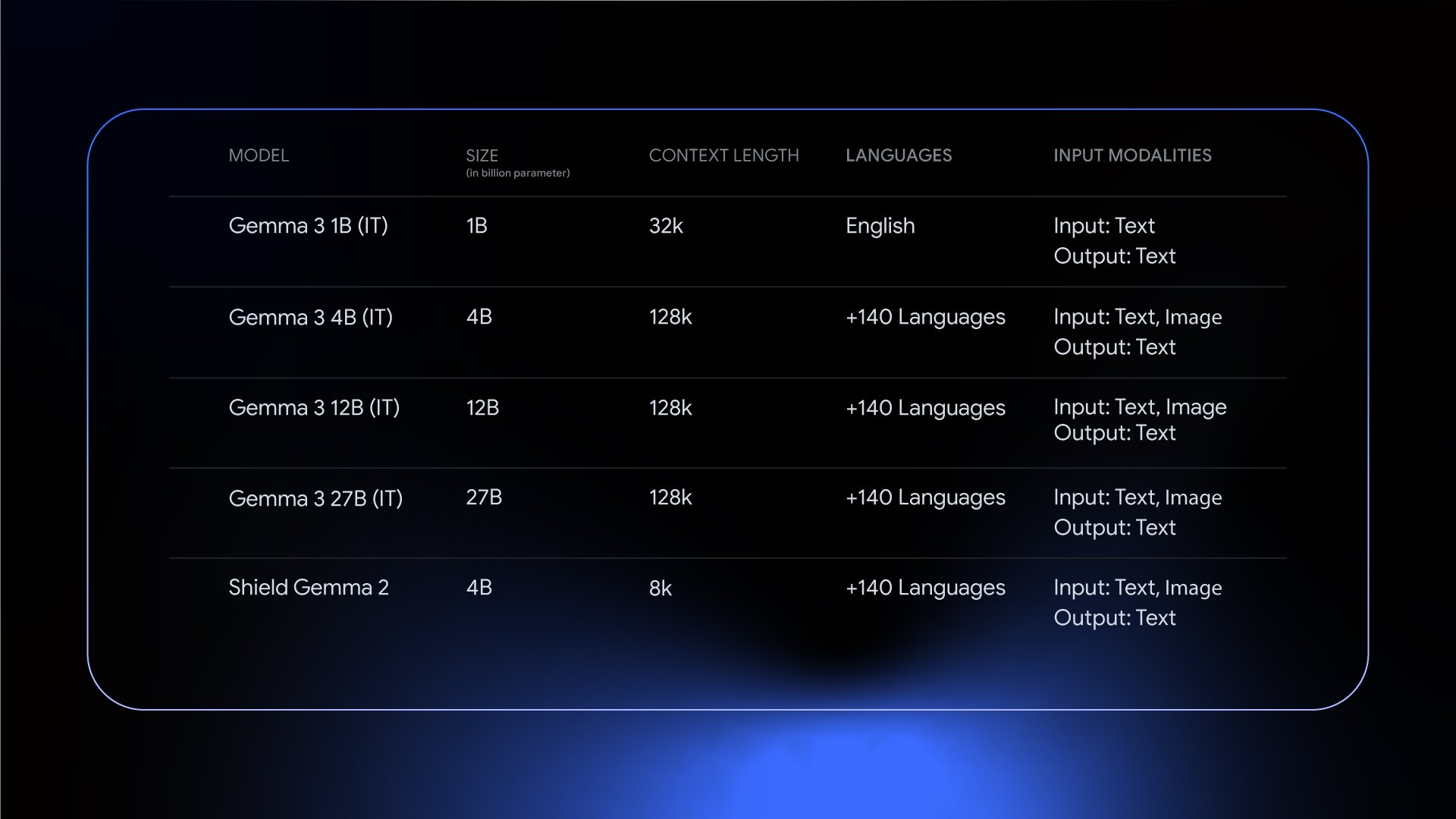
The model generates OpenSCAD code to render 3D files. We chose OpenSCAD for its open-source nature, ability to be rendered on-device or in-browser, and its token efficiency.
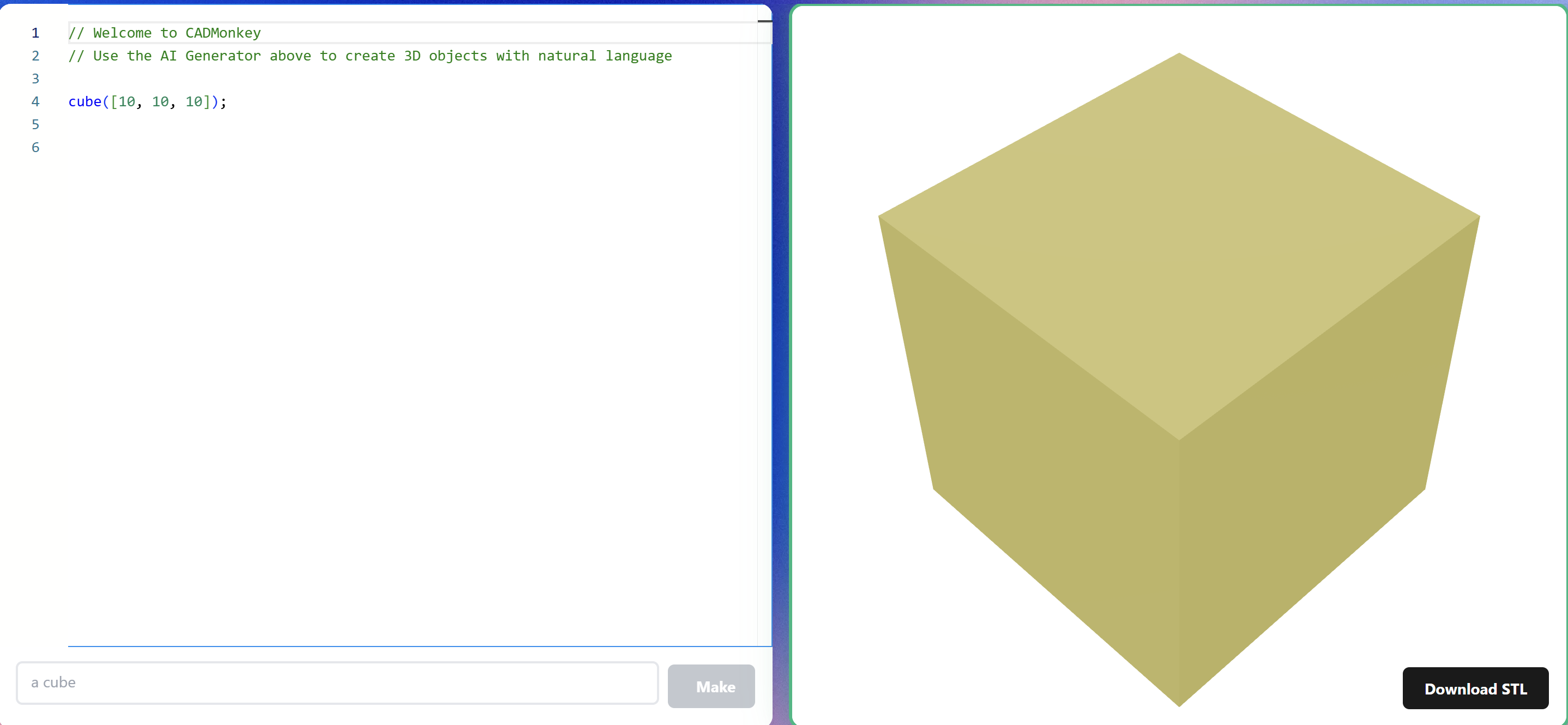
Dataset Generation
If there is one thing you take away from reading this: a model is only as good as its dataset.
We created a synthetic dataset using a pipeline: generate a list of common object names → ask a Large Language Model (Kimi) to generate OpenSCAD code → render the code → use a VLM (Qwen2.5-VL) to judge the output for resemblance.
The result: ThomasTheMaker/Synthetic-Object-v3 — the first synthetically generated & reviewed OpenSCAD dataset of large quantity on the internet (35k rows of verified data).

Browse the dataset: kdataset.web.app
Training
Fine-tuned Gemma3 270M, 1B & 4B models using Unsloth 4-bit finetuning with the prompt: "hey cadmonkey, make me a {object name}"

Output models converted to GGUF with q8 quantization. Everything available at hf.co/collections/ThomasTheMaker/cadmonkey
Results

- 75-80% rendering rate (does the code render?)
- 20-30% VLM judge rate (does it look right?)
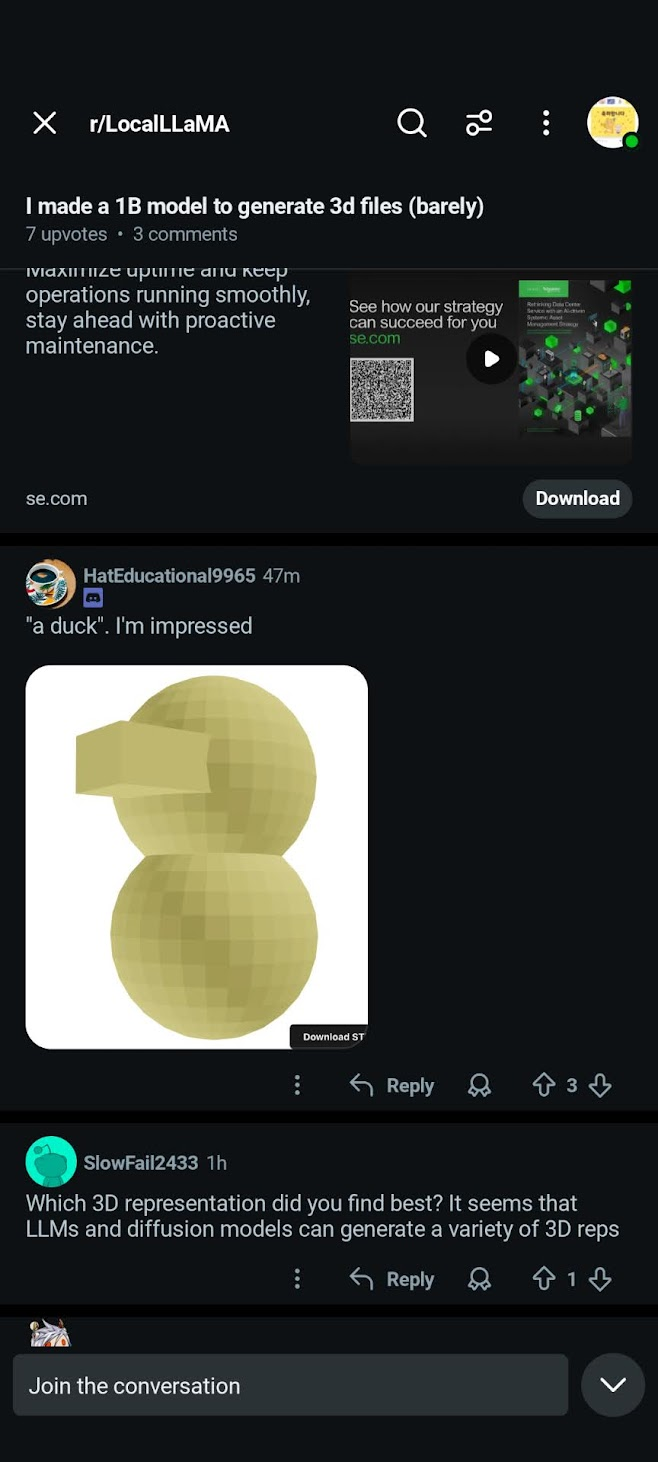
- 380+ models created in the first 12 hours of launching on Reddit
- Running on Modal for ~2¢ per prompt
A user successfully made a duck, which I'm very proud of:
v2: Example Diversification
In v2, model performance truly improved when we scaled the dataset vertically — using the same number of objects but scaling up the number of examples per object and the diversity of teacher models.

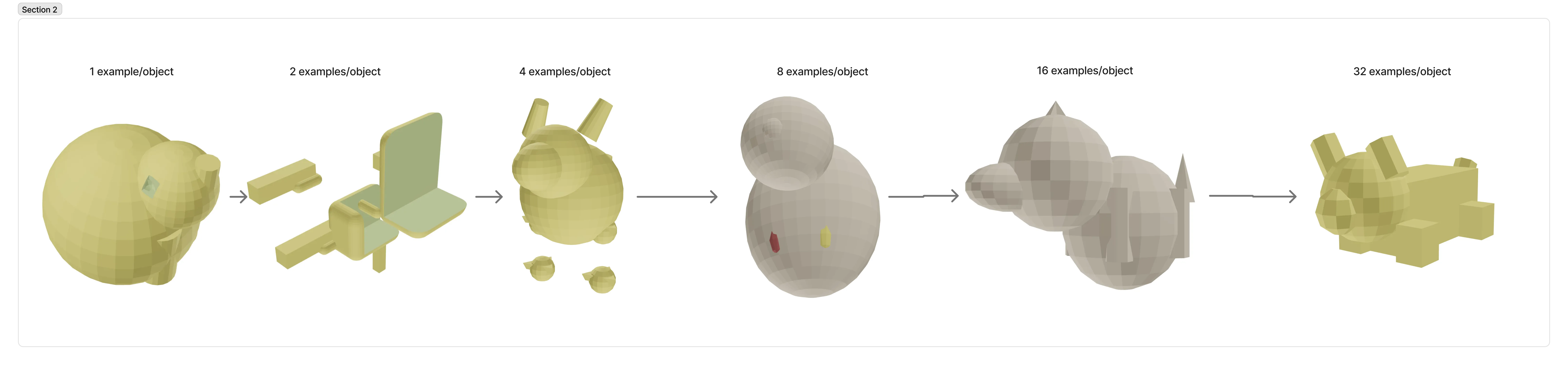
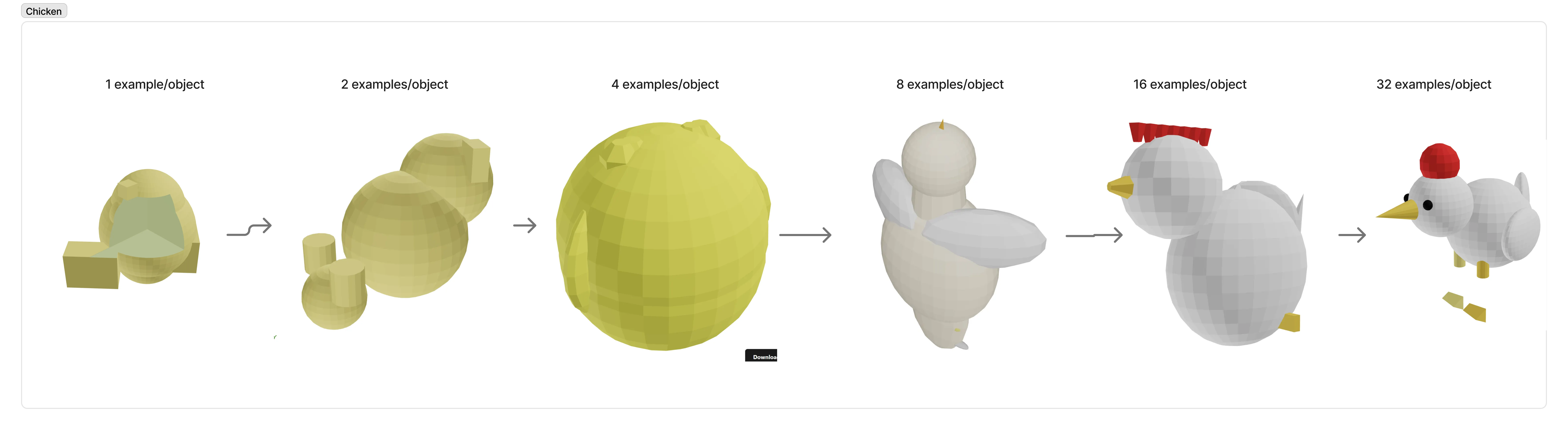
The Takeaway
I know it's cliché, but you can just make things! 5 years ago, this would have cost 5 figures and a team of 20 scientists. I ran the whole experiment over 3 weekends, using $500 in credits.
You really can just do things. You just have to be crazy enough to start.
Try It
- Web app: cadmonkey.web.app
- CLI tool: github.com/ThomasVuNguyen/MakeMe
- Models & data: hf.co/ThomasTheMaker