TinyGSM

Dumb model trained on simple math = smarter model?
Background
In 2023, the TinyGSM paper from Microsoft showed that training a Small Language Model on Grade School Math helps it out-perform much larger models on the GSM8K math benchmark.
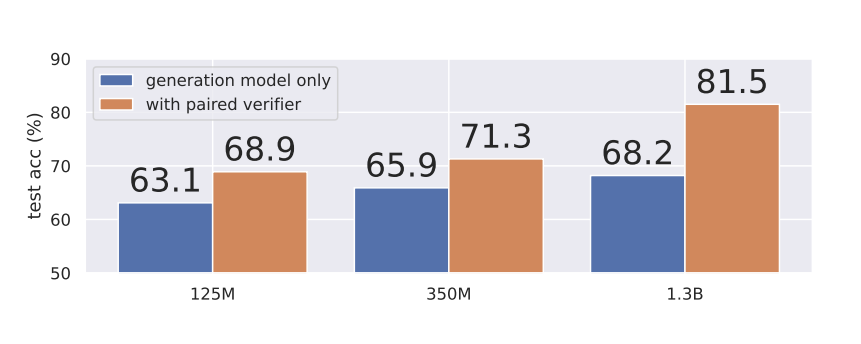
This was achieved by generating synthetic data from GPT-3.5 and training fine-tuned small models on that data. The fine-tuned model uses code to solve math problems.

My Approach: Quality & Diversity
Since 2023, there are wayyyy more Large Language Models and they are magnitudes better than GPT-3.5.
After reading a BabyAGI Paper about how teacher model diversity improves the student fine-tuned models, I decided to replicate the TinyGSM experiment with multiple high-quality teacher models:
- GPT 4.1, GPT 4.1 mini & GPT 4.1 nano (Azure AI Foundry)
- o4-mini (Azure AI Foundry)
- Llama3.3 70B (AWS Bedrock)
- Mixtral 8x7B (AWS Bedrock)
- Deepseek R1 (Cloudrift)
- Llama3.1 8B (Local GPU)
How to Pay for All This?

The original TinyGSM dataset contains 1.8B tokens (12 million question-answer pairs) and costs $3,600 to generate. Unlike Microsoft, I'm a startup founder. So I tried to do this as cheaply as possible:
- Azure AI Foundry: $1,000 in Microsoft Startup credits
- AWS Bedrock: $200 for mentoring at an AWS Hackathon
- Prime Intellect: $2,000 from Inflection Grant
- CloudRift: $800 in GPU credits
Overall $1,100 in cloud credits were spent.
Synthetic Data Generation

After running the generator for 7 days straight on my Mac Mini, I created 12 TinyGSM sub-datasets in three types:
- Instructed: LLM given explicit examples of how code should be generated
- No-example: No example given, code is free-style
- Reasoning: Reasoning LLM answers with their reasoning chains
Data Quality Findings
- GPT4.1 & GPT4.1 mini: Almost 100% correct responses
- o4-mini & Deepseek R1: Amazing reasoning capabilities
- Llama3.3 70B & Llama3.1 8B: Frequently correct but overly verbose
- Mixtral 8x7B: Quality is horrible, non-working code & missing details
- GPT 4.1 nano: Also bad quality
When given no examples, model responses are more verbose and less correct. When given a chance to reason, models perform much better.
Model Fine-tuning

Fine-tuning a Gemma3-270M model — small enough to run on Raspberry Pi 2 W and insanely fast on Orange Pi 5. Using Unsloth for fine-tuning.